Data Mining Term Project (Fall 2019)
Movie Search and Classifier
Phase 1: Movie Search
Demo LinkGitHub Link
Dataset
The dataset contains metadata for 45,000 movies listed in the Full MovieLens Dataset. The dataset consists of movies released on or before July 2017. Data points include cast, crew, plot keywords, budget, revenue, posters, release dates, languages, production companies, countries etc. https://www.kaggle.com/rounakbanik/the-movies-dataset
Pre-processing
In the pre-processing step, for each document in the dataset, we create
- unique_tokens: this is the set of all the tokens in the all the documents.
unique_tokens = {..., 'hanna', 'adventur', 'trap', 'syndic', 'scene', 'sibl', 'asid', 'glo', ...} - document_frequency: this stores the count of documents a token in present in.
document_frequency = {..., 'buzz': 1, 'differ': 1, 'onto': 1, 'woodi': 1, 'asid': 1, 'stori': 1, 'live': 2, ...} - postings: this stores the list of documents a token is present in, along with the number of occurences in that document.
postings = {..., 'hamm': {'198185': 1, '68139': 1}, 'pathway': {'159012': 1, '179340': 1, '376233': 1, '318832': 1, '440249': 1}, 'cultura': {'159012': 2}, ...} - lengths: this stores the length of each document.
lengths = {..., '805': 25, '34584': 34, '34636': 26, '2182': 34, '28070': 20, ...}
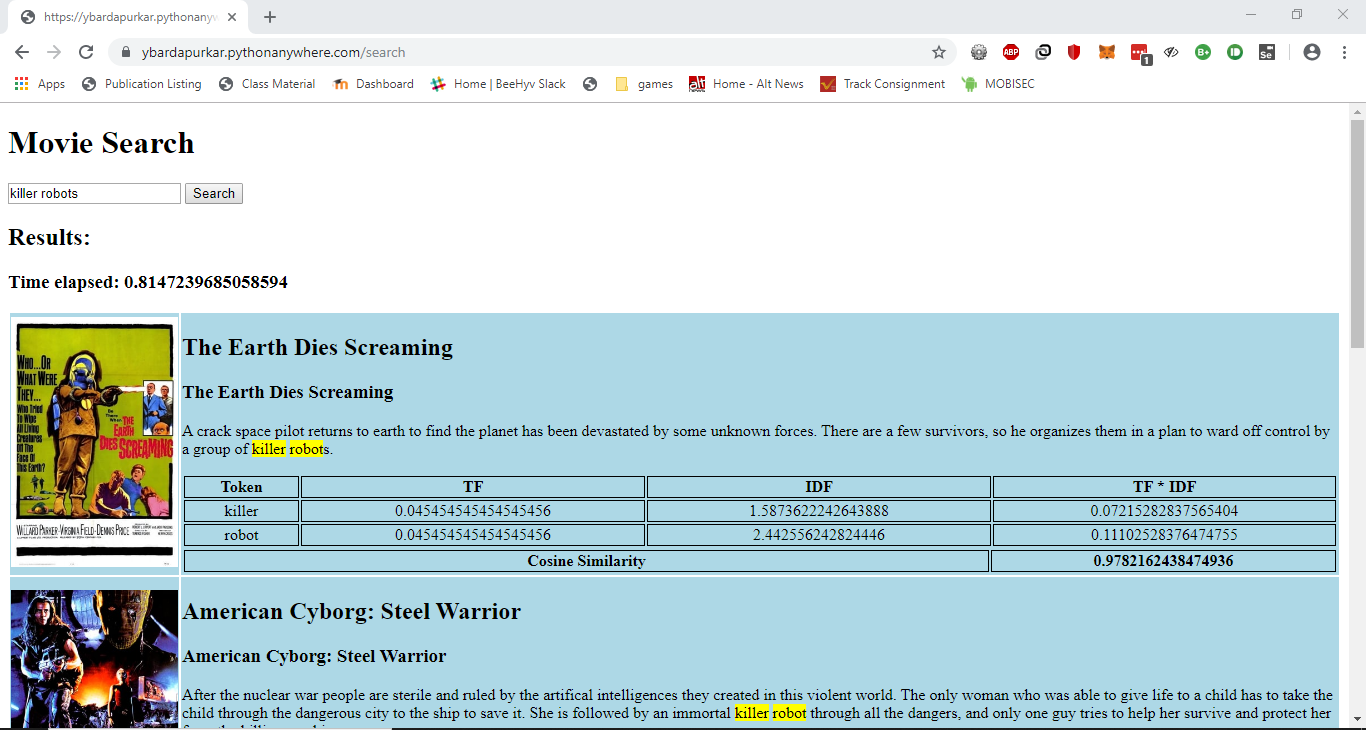
First, the query entered by the user is tokenized, and for each query token, the list of all the documents the token is present in is returned. Then, the document vector is created using the following formulae.
TF of a token in a document is calculated by the formula:
tf = self.postings[query_term][movie_id] / self.lengths[movie_id]IDF of a token is calculated by the formula:
idf = log10(len(self.lengths) / self.document_frequency[query_term])Documents are ranked by their score of cosine similarity based on the query tokens.
dot(query_vector, document_vectors[movie_id]) / (norm(query_vector) * norm(document_vectors[movie_id]))Finally, the documents are sorted by the decreasing order of the score, and top five results are returned.
Contributions
- Highlighting the tokens from the search query that are searched in the inverted index
- Displaying the TF and IDF scores of the tokens and Cosine Similarity of the results with the input query
The biggest challenge faced in the project was deploying the Flask app on PythonAnywhere. Because the pre-processing takes a very large amount of time, the deployment would always time-out. This was mitigated by using the Pickle library in python.
Pickle is a serialization and deserialization library, which can serialize or deserialize python variables to store them into files, or read them from files. The pre-processing step was carried out in the local machine and the resulting pickle data files were created, so that whenever the project was run, the pre-processing step could be skipped after the initial run, and the pre-processing data would simply read from the file. This decreased the app deployment time from several minutes to a few seconds, and also solved the time-out problem in PythonAnywhere.
References
- https://www.stackoverflow.com
- https://www.youtube.com/watch?v=Flpj_D8b1Vg
- https://www.freecodecamp.org/news/how-to-process-textual-data-using-tf-idf-in-python-cd2bbc0a94a3/
- https://github.com/BhaskarTrivedi/QuerySearch_Recommentation_Classification
- https://docs.python.org/3.4/library/pickle.html